

目录
快速导航-
专题 | 政府开放数据平台FAIR原则评估指标体系及实证研究
专题 | 政府开放数据平台FAIR原则评估指标体系及实证研究
-
专题 | 期刊论文支撑数据FAIR原则的应用评估与案例分析
专题 | 期刊论文支撑数据FAIR原则的应用评估与案例分析
-
专题 | 基于FAIR原则的数据期刊开放共享与关联模型研究
专题 | 基于FAIR原则的数据期刊开放共享与关联模型研究
-
情报理论与前瞻观点 | 信息资源管理一级学科更名背景下研究主题历史演化及未来发展趋势研究
情报理论与前瞻观点 | 信息资源管理一级学科更名背景下研究主题历史演化及未来发展趋势研究
-
情报理论与前瞻观点 | 中美图书情报领域学科话语权的比较研究
情报理论与前瞻观点 | 中美图书情报领域学科话语权的比较研究
-
情报分析与技术创新 | 基于知乎平台内容挖掘的元宇宙公众感知研究
情报分析与技术创新 | 基于知乎平台内容挖掘的元宇宙公众感知研究
-

情报分析与技术创新 | 基于机器学习分类算法的高质量专利成果筛选研究
情报分析与技术创新 | 基于机器学习分类算法的高质量专利成果筛选研究
-
数据共享与数据治理 | 价值共创视角下在线医疗社区医生群组划分与特征分析
数据共享与数据治理 | 价值共创视角下在线医疗社区医生群组划分与特征分析
-

数据共享与数据治理 | 面向科技文献多维语义组织的混合倒排索引构建方法
数据共享与数据治理 | 面向科技文献多维语义组织的混合倒排索引构建方法
-

信息行为与用户研究 | 平台特征对跨社交媒体UGC信息分享行为的影响机理研究
信息行为与用户研究 | 平台特征对跨社交媒体UGC信息分享行为的影响机理研究
-
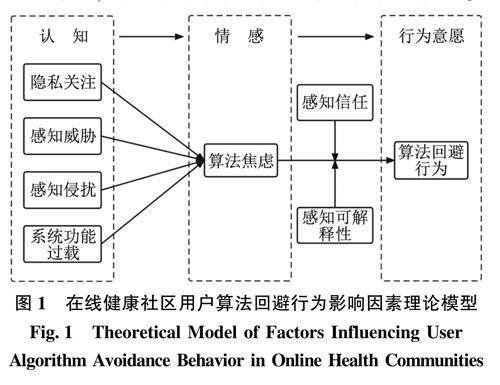
信息行为与用户研究 | CAC范式下在线健康社区用户算法回避行为的影响因素研究
信息行为与用户研究 | CAC范式下在线健康社区用户算法回避行为的影响因素研究
-

信息传播与信息规制 | 基于改进HK模型的社交用户观点演化预测研究
信息传播与信息规制 | 基于改进HK模型的社交用户观点演化预测研究
-

信息传播与信息规制 | 网络舆情群体观点提取模型构建与实证研究
信息传播与信息规制 | 网络舆情群体观点提取模型构建与实证研究
-

信息计量与科学评价 | 文化强国背景下中国学术话语权评价体系的构建与提升路径探析
信息计量与科学评价 | 文化强国背景下中国学术话语权评价体系的构建与提升路径探析
-

信息计量与科学评价 | 基于BP神经网络的学术论文评价模型研究
信息计量与科学评价 | 基于BP神经网络的学术论文评价模型研究




















 登录
登录