

目录
快速导航-
专家访谈 | 专家访谈:破局 “技术热”与“传统冷”
专家访谈 | 专家访谈:破局 “技术热”与“传统冷”
-
专家访谈 | 面向国家战略需求:让技术“热”得其所,让传统“冷”中升温
专家访谈 | 面向国家战略需求:让技术“热”得其所,让传统“冷”中升温
-
专家访谈 | ‘冷”与“热”融合之道:以传统之根涵养技术之器以技术之器壮大传统之根
专家访谈 | ‘冷”与“热”融合之道:以传统之根涵养技术之器以技术之器壮大传统之根
-
专家访谈 | 技术“热”与传统“冷”的融通性思考:学科价值与时代使命的交融统一
专家访谈 | 技术“热”与传统“冷”的融通性思考:学科价值与时代使命的交融统一
-
专家访谈 | 优化人才培养生态:破解“追热点”与“丢根基” 之困
专家访谈 | 优化人才培养生态:破解“追热点”与“丢根基” 之困
-
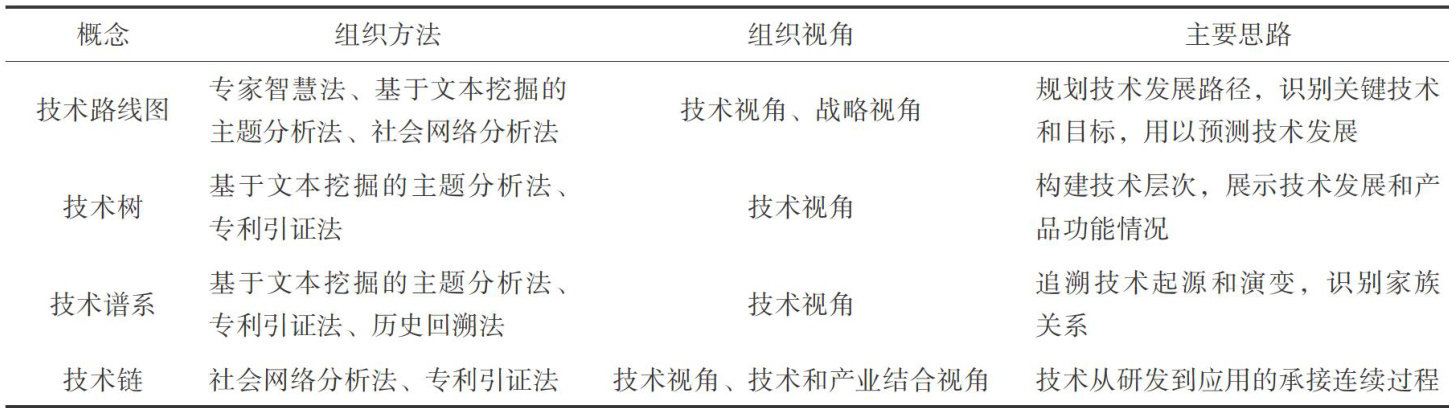
情报理论与前瞻观点 | 产业链视角下的技术体系构建方法研究
情报理论与前瞻观点 | 产业链视角下的技术体系构建方法研究
-
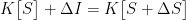
情报理论与前瞻观点 | 融合与统一:情报的数学原理
情报理论与前瞻观点 | 融合与统一:情报的数学原理
-
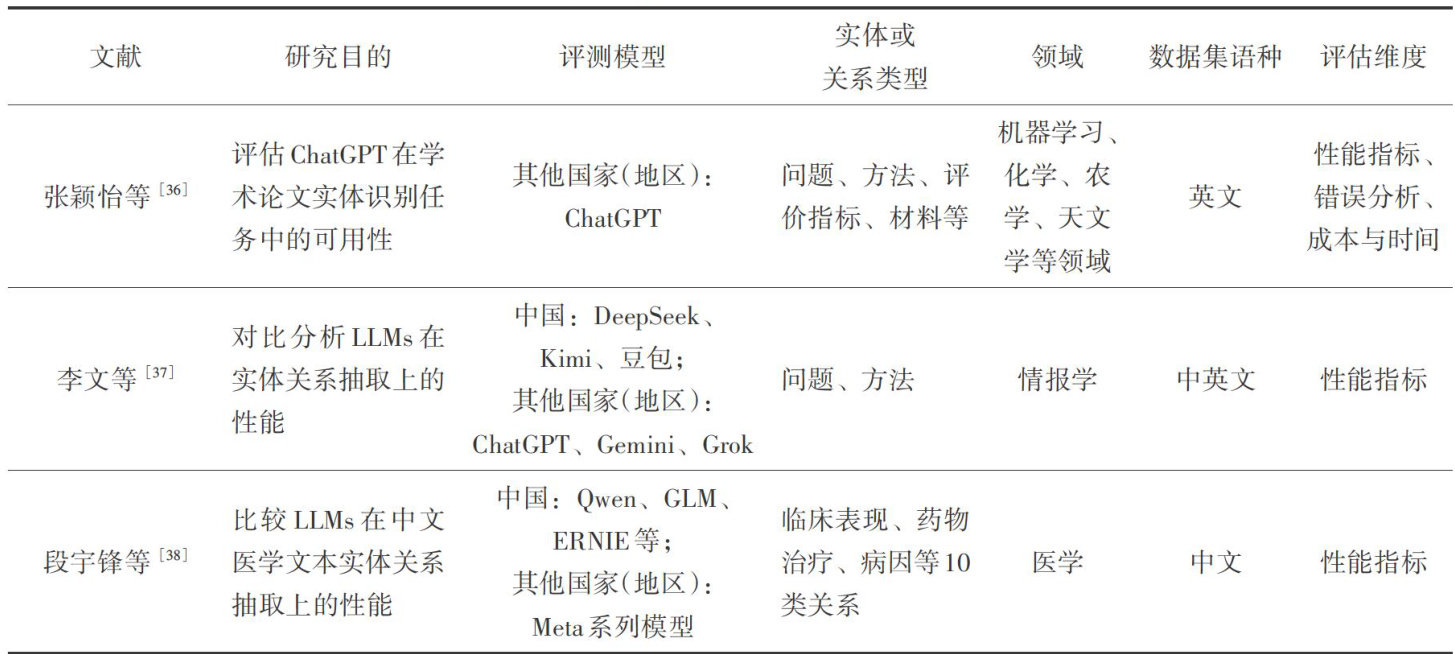
数据智库与知识服务 | 中国大语言模型知识实体抽取能力评测
数据智库与知识服务 | 中国大语言模型知识实体抽取能力评测
-
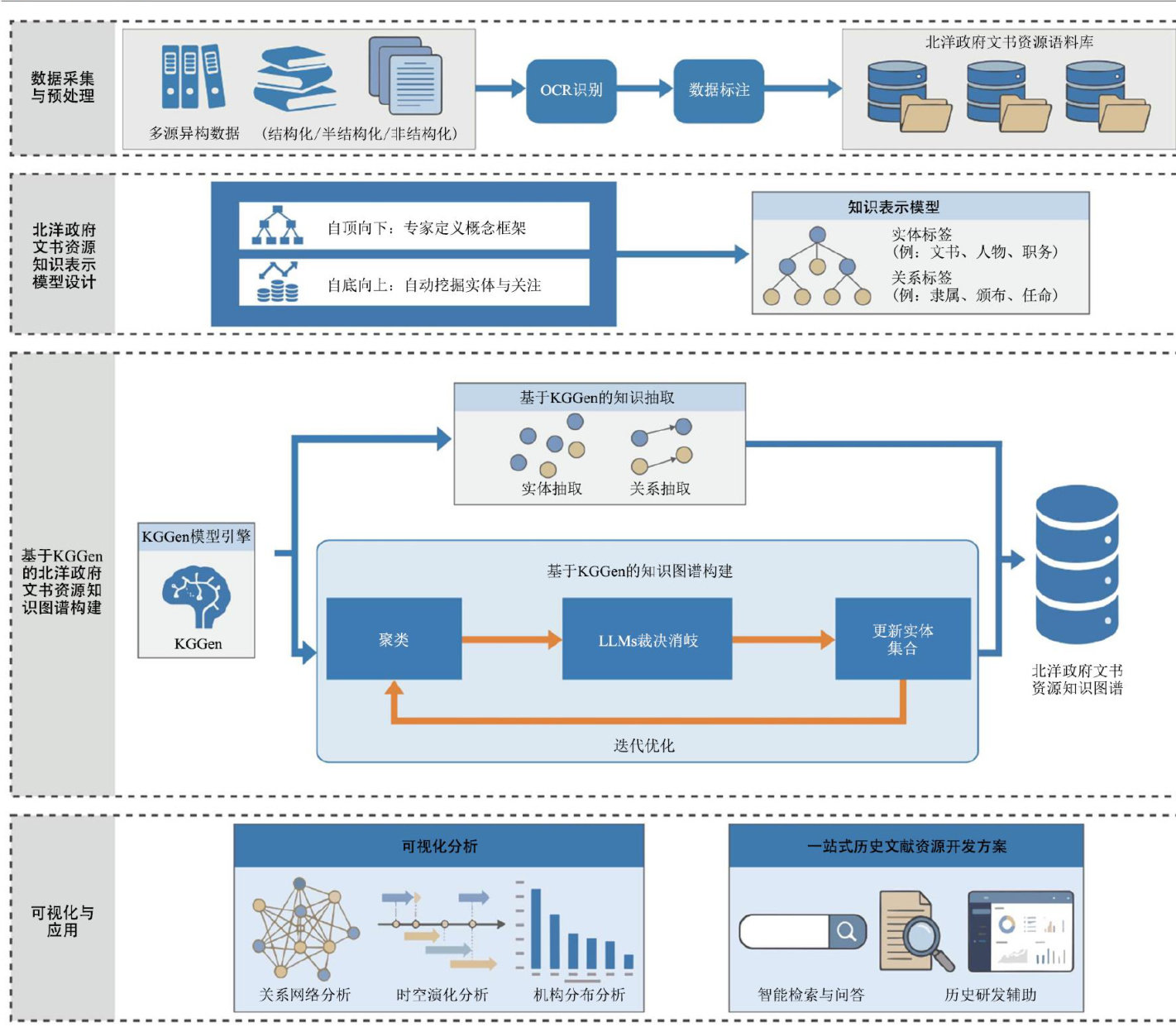
数据智库与知识服务 | 大语言模型驱动的北洋政府文书资源知识图谱构建研究
数据智库与知识服务 | 大语言模型驱动的北洋政府文书资源知识图谱构建研究
-
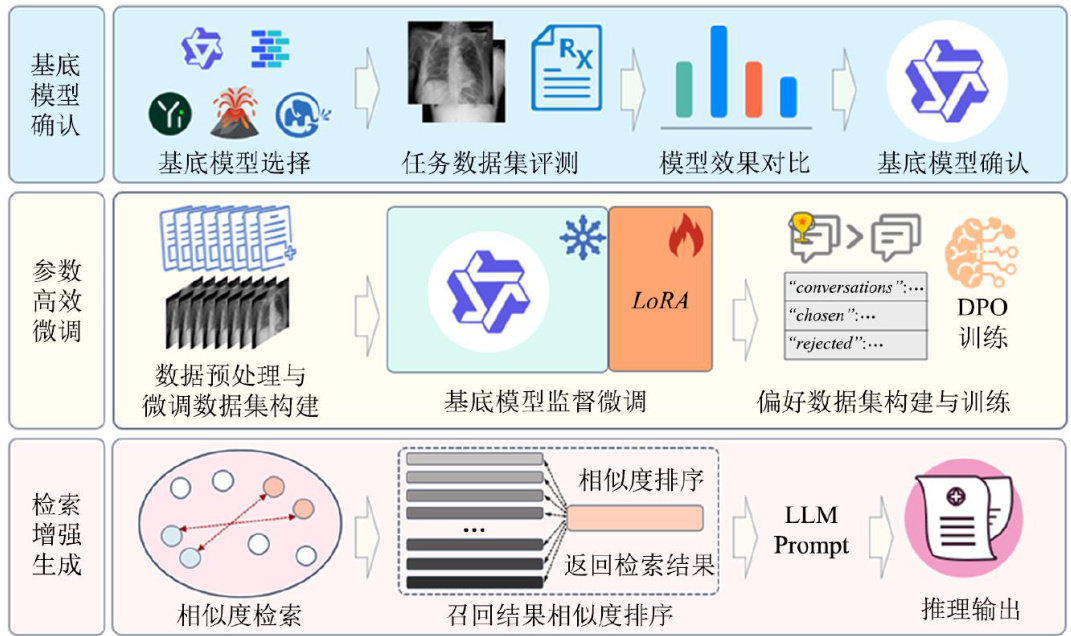
数据智库与知识服务 | AIGC驱动的医疗健康领域知识服务模式研究
数据智库与知识服务 | AIGC驱动的医疗健康领域知识服务模式研究
-

人智交互与信息行为 | 人智交互情境下用户在线心理健康同伴支持效果评价研究
人智交互与信息行为 | 人智交互情境下用户在线心理健康同伴支持效果评价研究
-

人智交互与信息行为 | 社交媒体虚假信息纠正意愿的影响因素
人智交互与信息行为 | 社交媒体虚假信息纠正意愿的影响因素
-

人智交互与信息行为 | 短视频的视觉化展示方式对用户购买行为的影响研究
人智交互与信息行为 | 短视频的视觉化展示方式对用户购买行为的影响研究
-
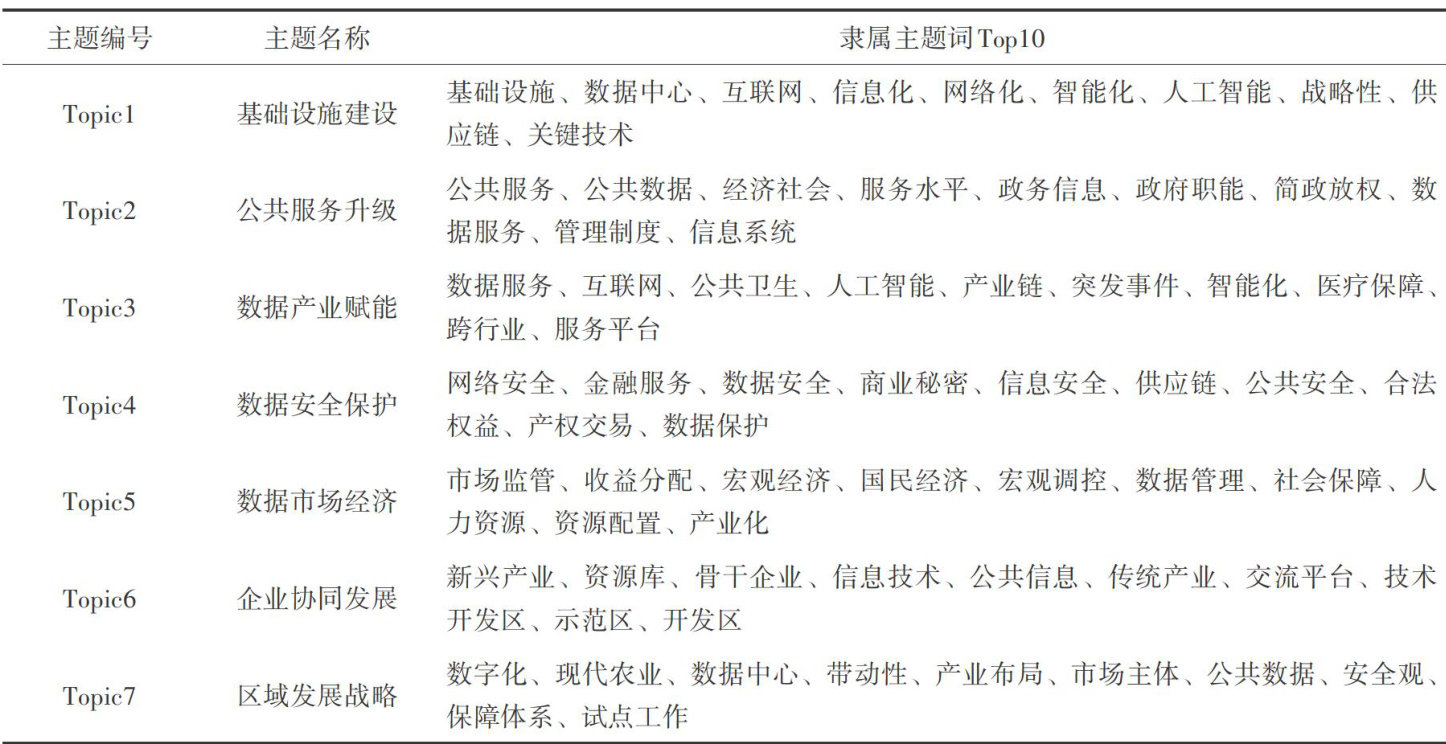
数据要素与数据治理 | 中国数据要素政策主题的嬉变逻辑及扩散动向分析
数据要素与数据治理 | 中国数据要素政策主题的嬉变逻辑及扩散动向分析
-
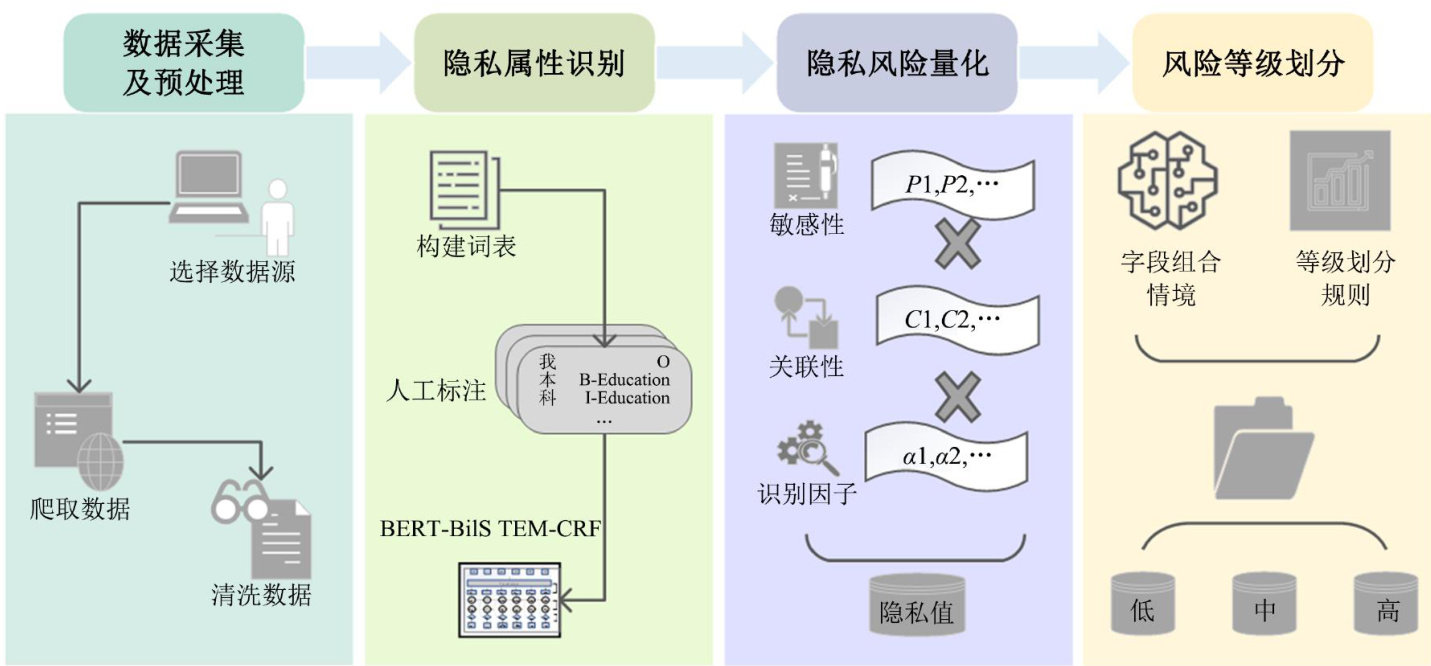
数据要素与数据治理 | 融合敏感性与关联性的隐私风险评估及实证研究
数据要素与数据治理 | 融合敏感性与关联性的隐私风险评估及实证研究
-
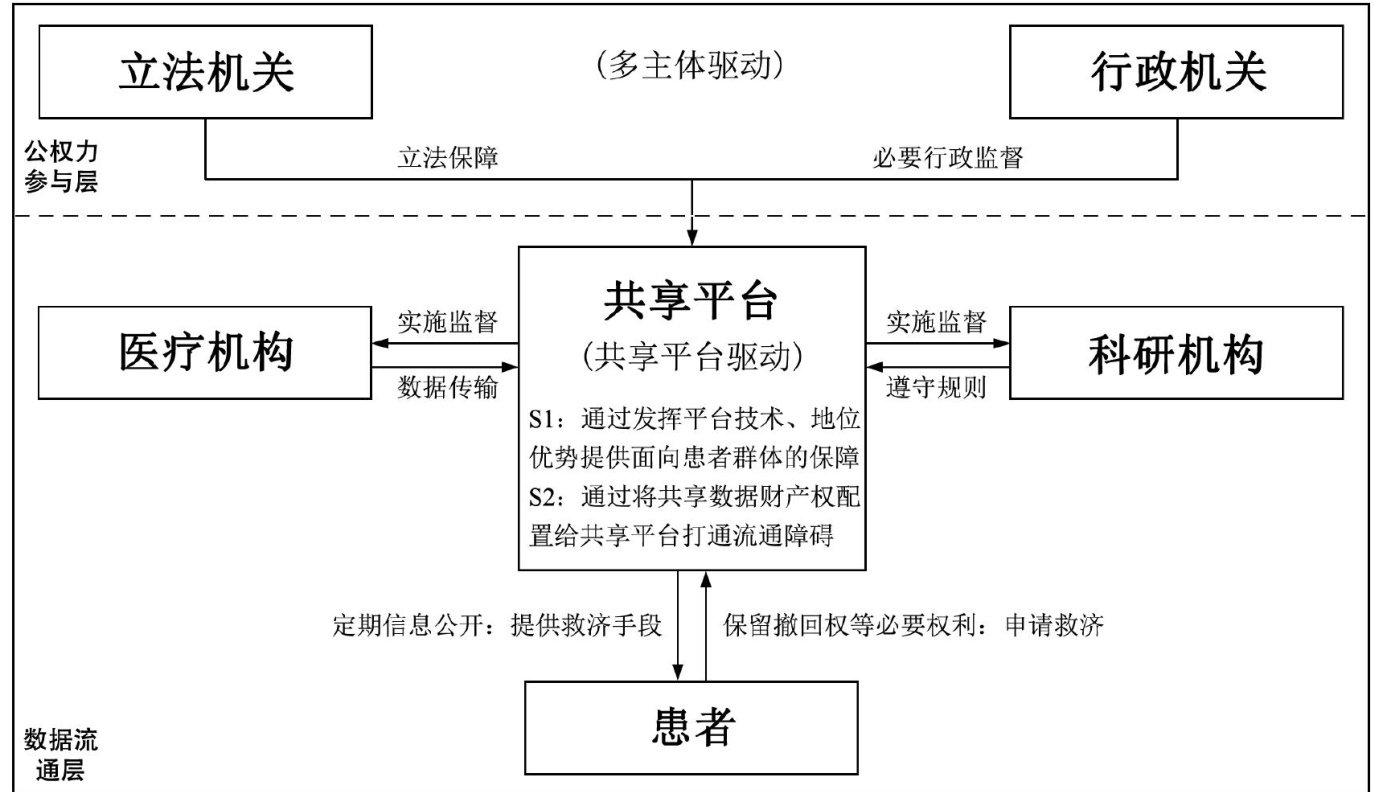
数据要素与数据治理 | 平台+多主体”双驱动模式下医疗数据共享规范化策略
数据要素与数据治理 | 平台+多主体”双驱动模式下医疗数据共享规范化策略
-
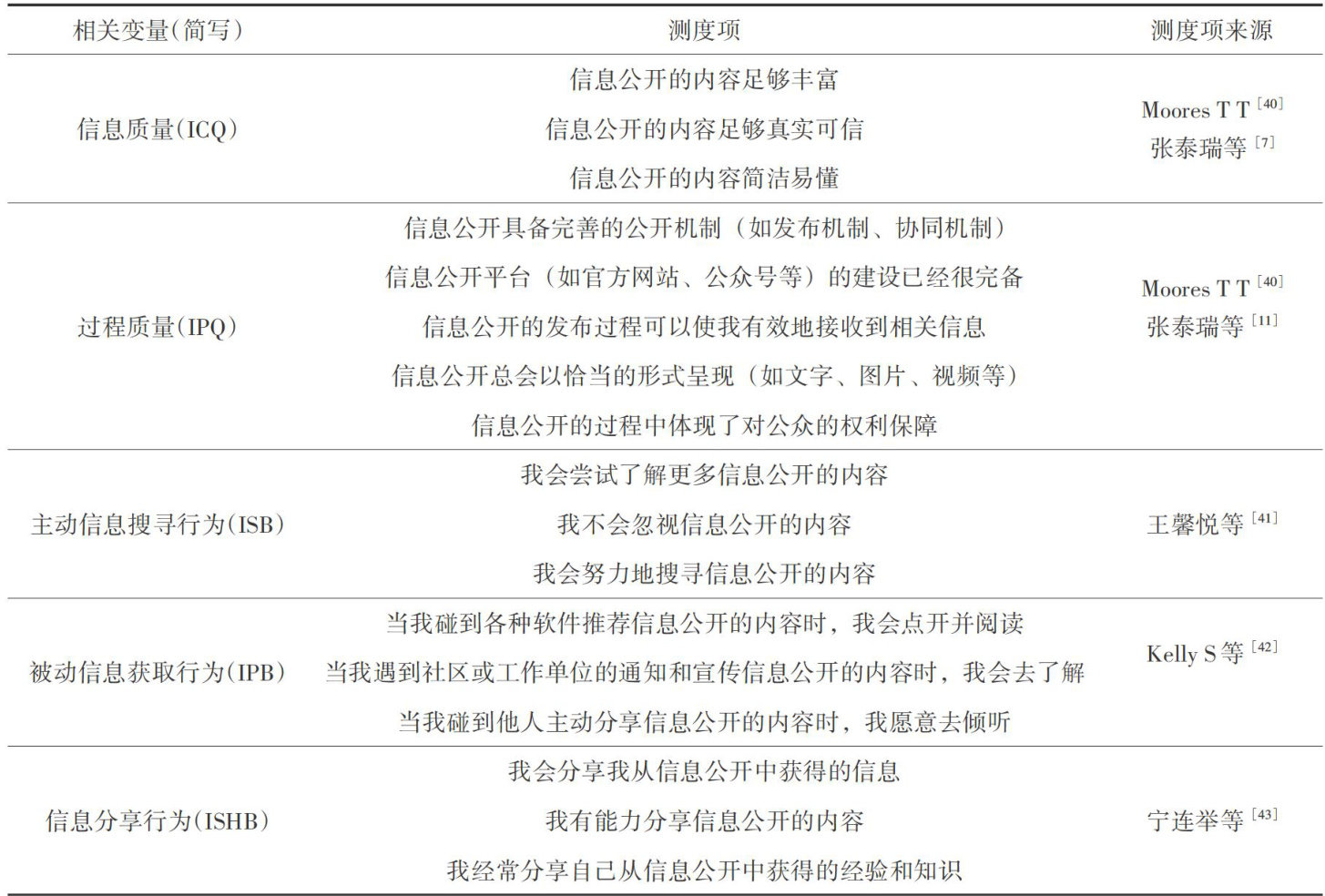
信息传播与信息规划 | 突发公共危机中信息公开赋能公众的路径
信息传播与信息规划 | 突发公共危机中信息公开赋能公众的路径
-

信息传播与信息规划 | 在线健康社区情境下算法感知对用户隐私披露意愿的影响机制研究
信息传播与信息规划 | 在线健康社区情境下算法感知对用户隐私披露意愿的影响机制研究
-
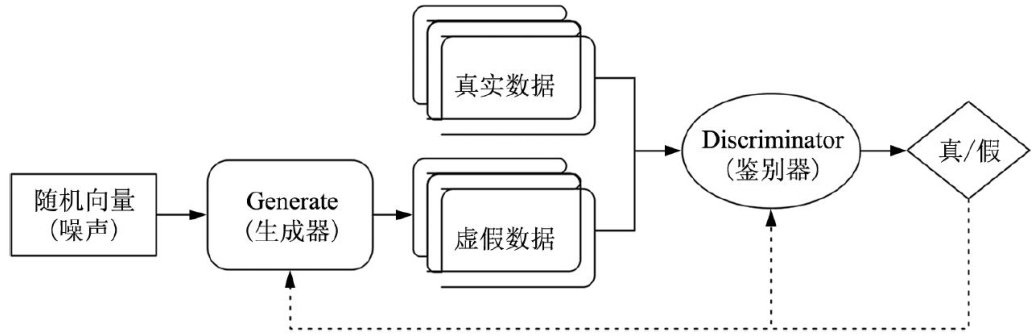
信息传播与信息规划 | 基于可解释性GAN与ChatGPT协同的网络健康谣言识别研究
信息传播与信息规划 | 基于可解释性GAN与ChatGPT协同的网络健康谣言识别研究













 登录
登录