

目录
快速导航-
专题 | 专题导语:多源融合 协同应用
专题 | 专题导语:多源融合 协同应用
-
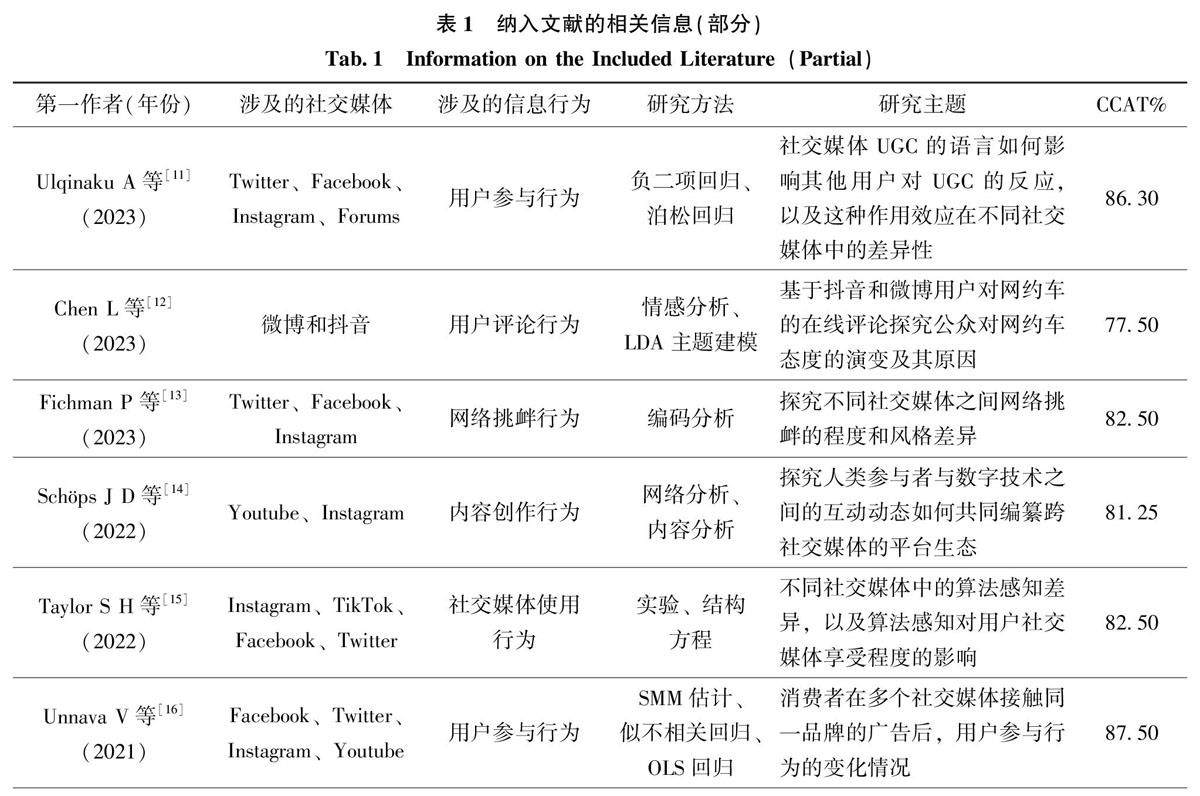
专题 | 用户跨社交媒体信息行为研究毕达天
专题 | 用户跨社交媒体信息行为研究毕达天
-

专题 | 跨社交媒体舆情关键节点识别方法及其实证研究
专题 | 跨社交媒体舆情关键节点识别方法及其实证研究
-

专题 | 融合跨平台用户偏好与异质信息网络的推荐算法研究
专题 | 融合跨平台用户偏好与异质信息网络的推荐算法研究
-

情报分析与技术创新 | 基于LDA2Vec-EERT的新兴技术主题多维指标识别与演化分析研究胡泽文
情报分析与技术创新 | 基于LDA2Vec-EERT的新兴技术主题多维指标识别与演化分析研究胡泽文
-
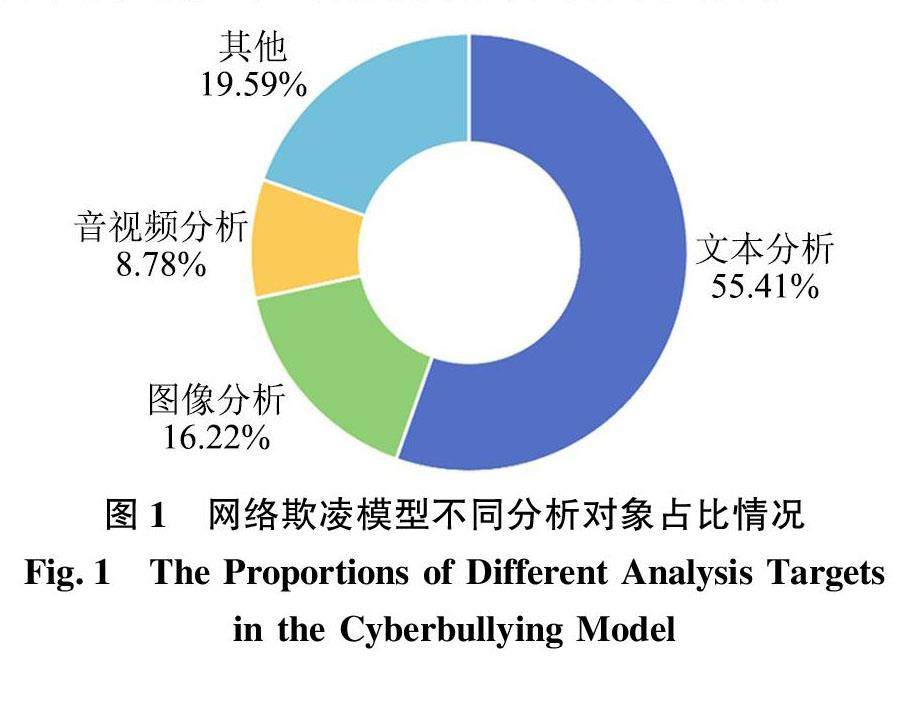
情报分析与技术创新 | 面向网络欺凌文本检测模型的算法解释及其故事化呈现研究
情报分析与技术创新 | 面向网络欺凌文本检测模型的算法解释及其故事化呈现研究
-
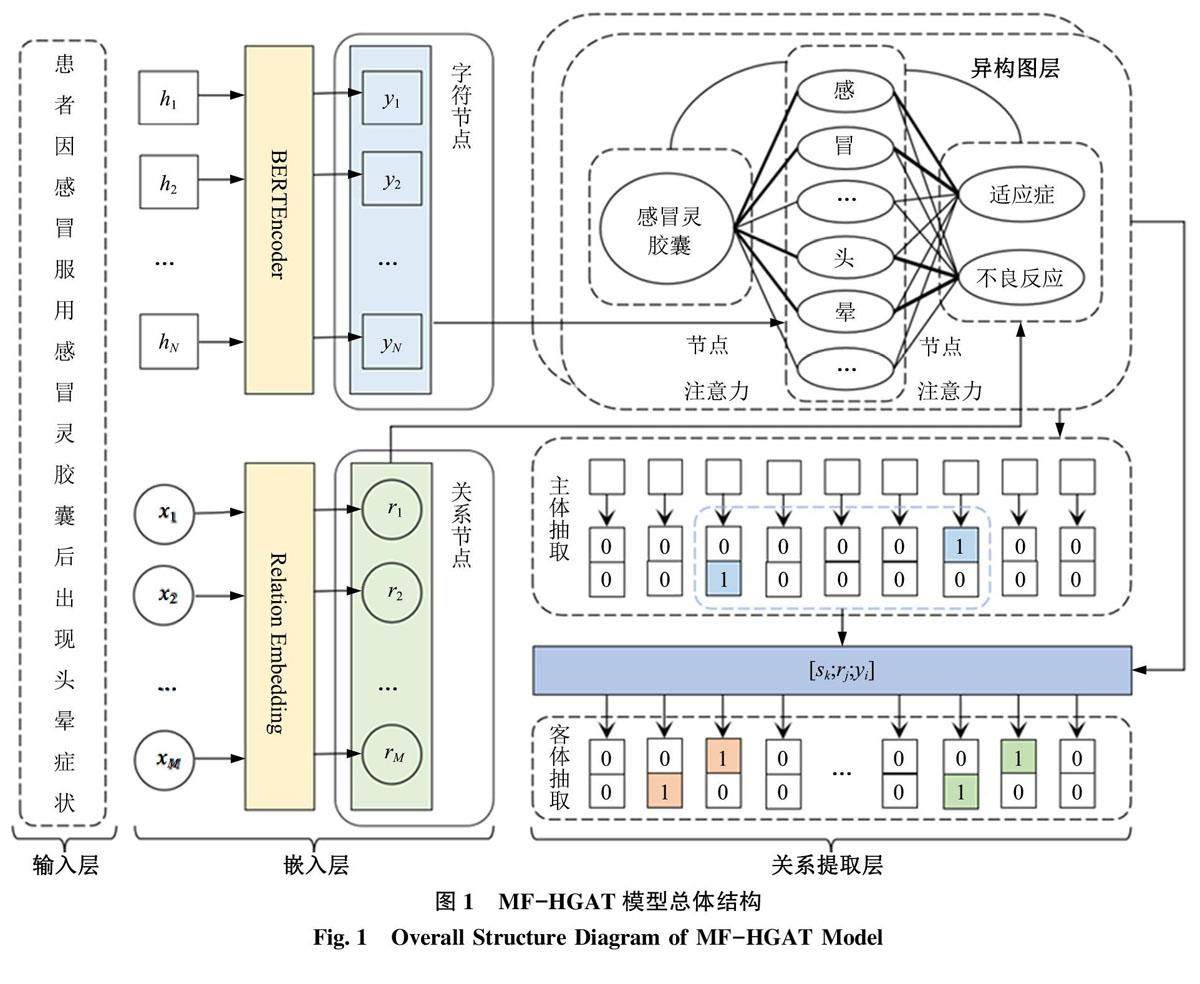
情报分析与技术创新 | 基于异构图注意力网络的药物不良反应实体关系联合抽取研究
情报分析与技术创新 | 基于异构图注意力网络的药物不良反应实体关系联合抽取研究
-

信息行为与用户研究 | 大学生学术信息搜寻挫折应对行为研究
信息行为与用户研究 | 大学生学术信息搜寻挫折应对行为研究
-
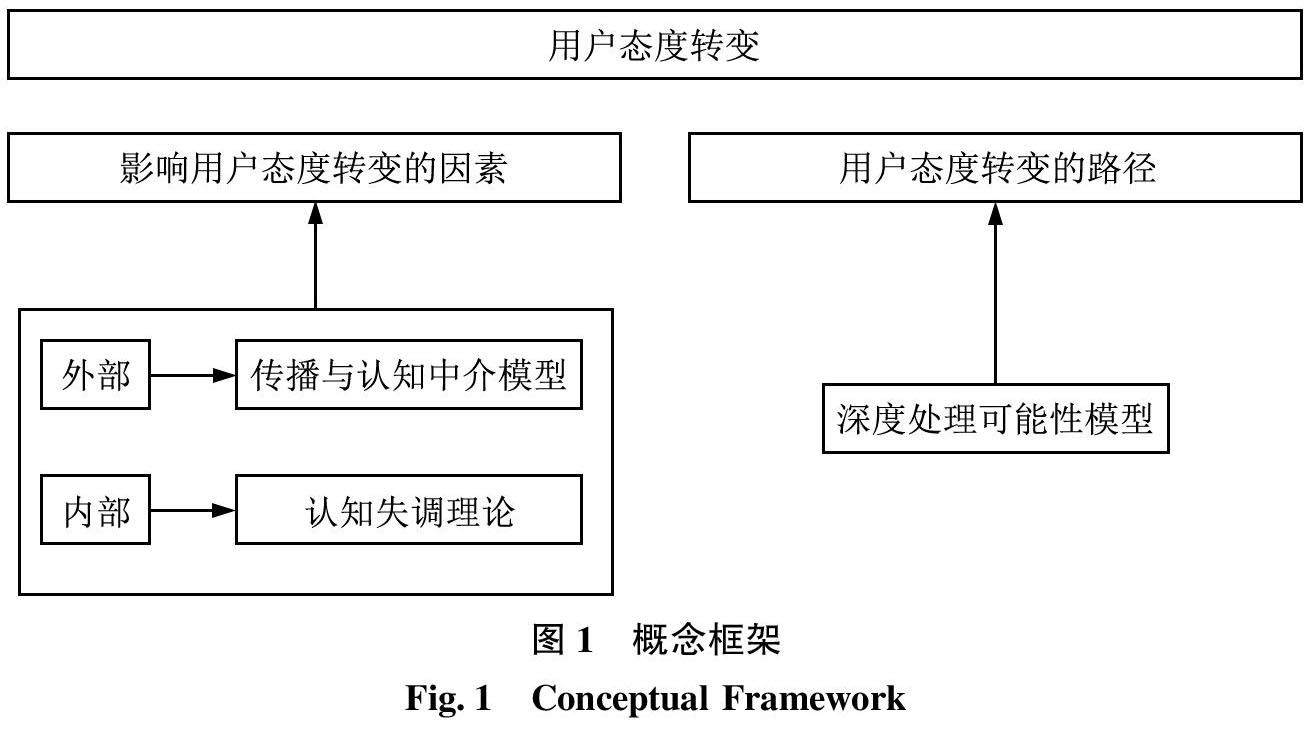
信息行为与用户研究 | 在线社区用户的说服交流与态度转变研究
信息行为与用户研究 | 在线社区用户的说服交流与态度转变研究
-

信息行为与用户研究 | 用户信息搜寻到信息规避的演化机制研究
信息行为与用户研究 | 用户信息搜寻到信息规避的演化机制研究
-

数据共享与数据治理 | 我国公共数据授权运营的实践进展调查与展望
数据共享与数据治理 | 我国公共数据授权运营的实践进展调查与展望
-

数据共享与数据治理 | 数字健康产业数据治理体系研究
数据共享与数据治理 | 数字健康产业数据治理体系研究
-

数据共享与数据治理 | 我国数据跨境流动协同治理现实困境及纾解路径研究
数据共享与数据治理 | 我国数据跨境流动协同治理现实困境及纾解路径研究
-

信息计量与科学评价 | 学术期刊评价中DEA方法的系统误差研究
信息计量与科学评价 | 学术期刊评价中DEA方法的系统误差研究
-

信息计量与科学评价 | 信息资源管理学科期刊知识交流效率测度及影响因素动态组态分析
信息计量与科学评价 | 信息资源管理学科期刊知识交流效率测度及影响因素动态组态分析




















 登录
登录